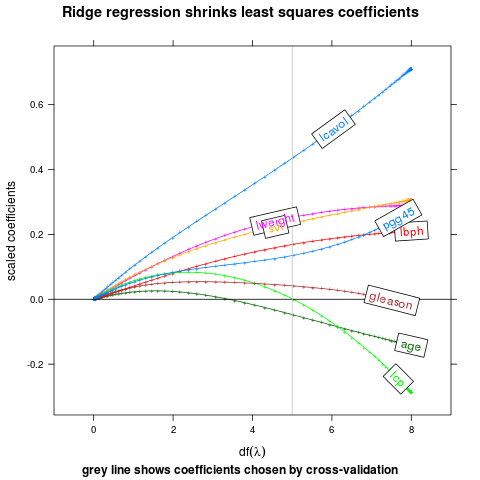
Draw a box with the label inside, at the point furthest away from the plot border and any other curve.
direct.label(p,"angled.boxes")
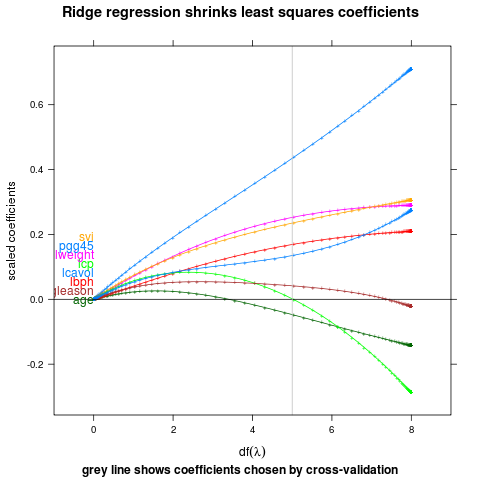
Label first points, bumping labels up if they collide.
direct.label(p,"first.bumpup")
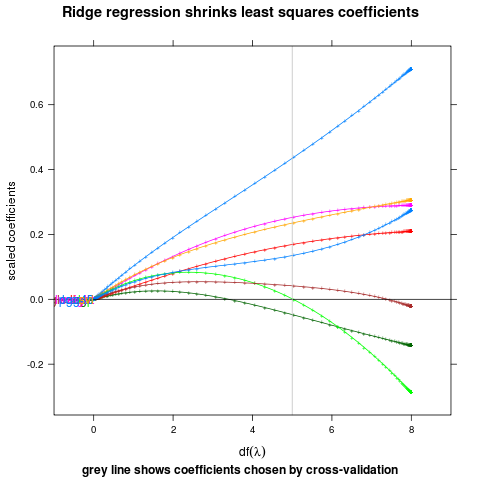
Positioning Method for the first of a group of points.
direct.label(p,"first.points")
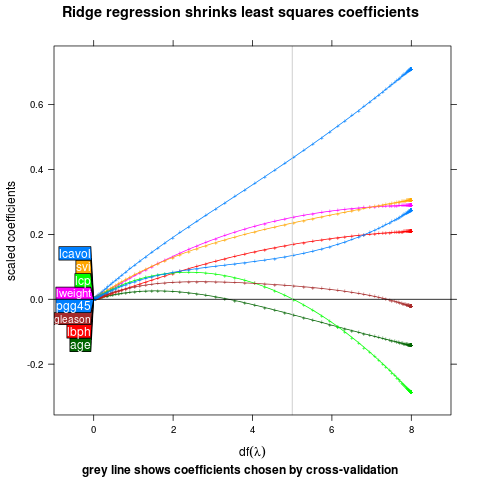
Draw a speech polygon to the first point.
direct.label(p,"first.polygons")
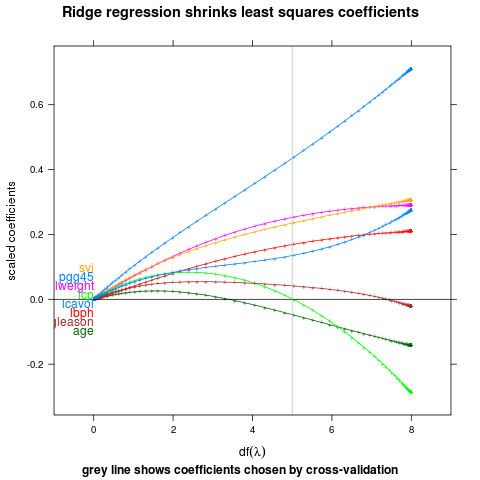
Label first points from QP solver that ensures labels do not collide.
direct.label(p,"first.qp")
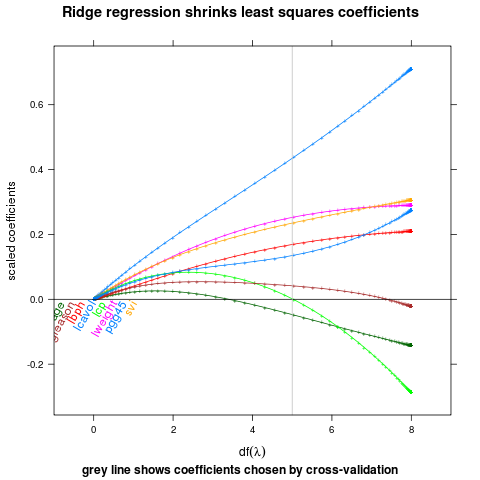
Label points at the zero before the first nonzero y value.
direct.label(p,"lasso.labels")
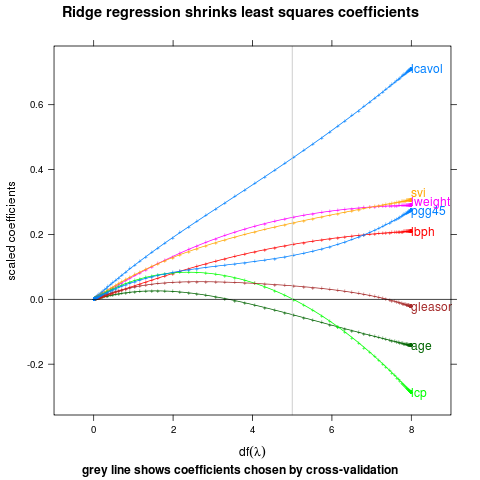
Label last points, bumping labels up if they collide.
direct.label(p,"last.bumpup")
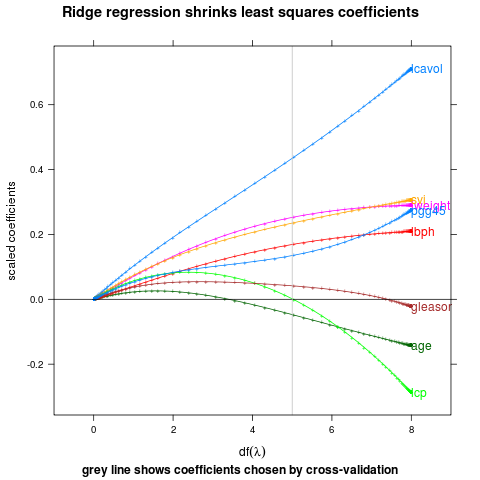
Positioning Method for the last of a group of points.
direct.label(p,"last.points")
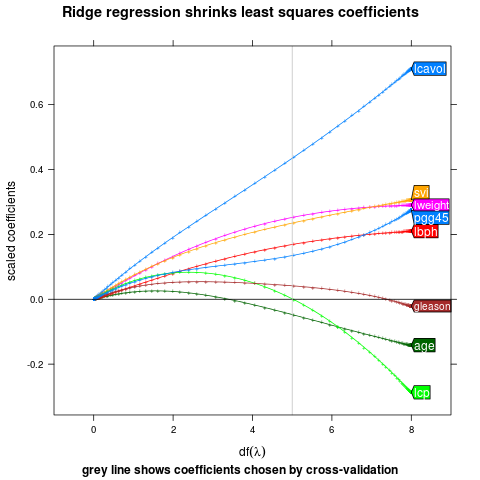
Draw a speech polygon to the last point.
direct.label(p,"last.polygons")
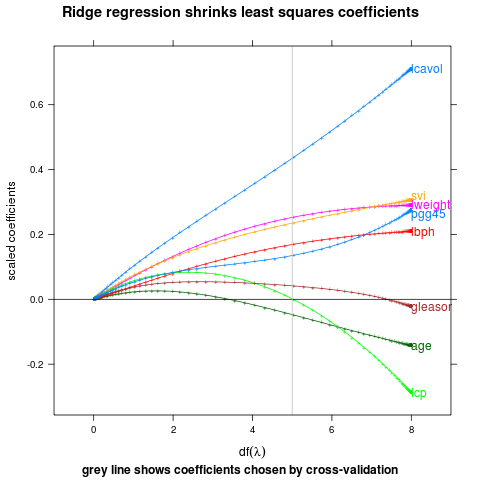
Label last points from QP solver that ensures labels do not collide.
direct.label(p,"last.qp")
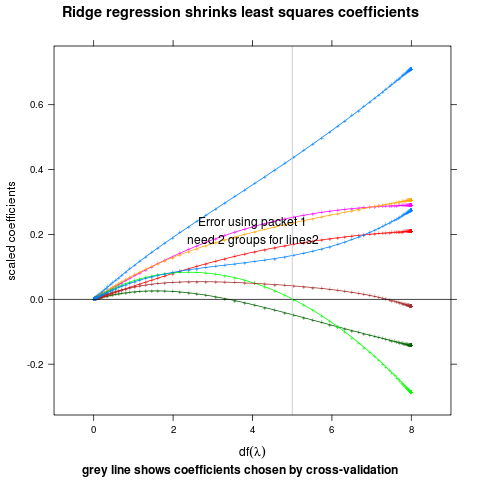
Positioning Method for 2 groups of longitudinal data. One curve is on top of the other one (on average), so we label the top one at its maximal point, and the bottom one at its minimal point. Vertical justification is chosen to minimize collisions with the other line. This may not work so well for data with high variability, but then again lineplots may not be the best for these data either.
direct.label(p,"lines2")
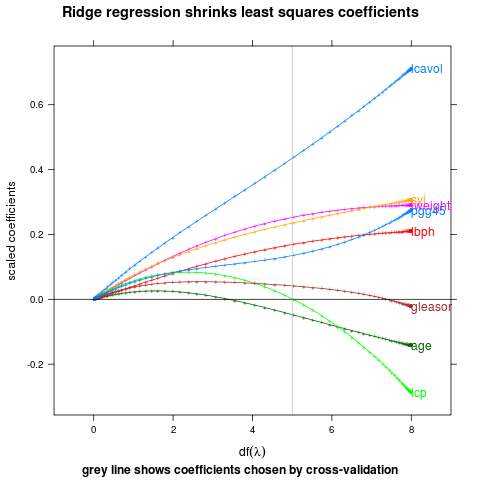
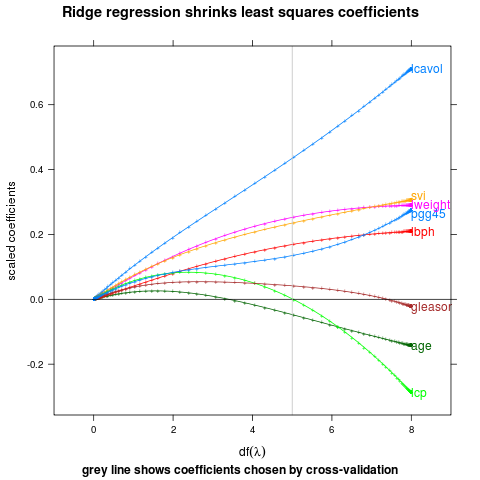
Do first or last, whichever has points most spread out.
direct.label(p,"maxvar.points")
Label first or last points, whichever are more spread out, and use a QP solver to make sure the labels do not collide.
direct.label(p,"maxvar.qp")