Mammouth tutorial
The goal of this post is to explain how to do parallel computations on Mammouth, the UdeS super-computer.
To login to mammouth, you need an account with the Digital Research Alliance of Canada. If you do not have one, then go to CCDB and register by following these application instructions. When you register, make sure to indicate the CCRI of your PI/professor/boss as your sponsor, so your compute time can be billed to their account. For me that is:
- userid: thocking
- account/project: def-thocking
- CCRI: gmt-235-04
As a part of registration, you need to setup two-factor authentication, which probably means downloading the Duo Mobile app on your telephone.
After I approve you on my account, you need to do another step on the web page Access Systems, if you want to access some newer cluster systems, for example Rorqual. Click the cluster name on the left, then click “I request access” and the “I accept” buttons below, if there are any.
Now on some cluster systems, you need to be physically at the
university, or on the VPN, but that is not the case for Mammouth. So
the next step is to just pull up a terminal and use ssh with your CCDB
user name (not your UdeS CIP), to host mp2.calculcanada.ca and make
sure to use the -Y flag if you want to use X forwarding.
(base) tdhock@maude-MacBookPro:~/tdhock.github.io(master)$ LC_ALL=C ssh -Y thocking@mp2.calculcanada.ca
Warning: Permanently added the ED25519 host key for IP address '204.19.23.216' to the list of known hosts.
Multifactor authentication is now mandatory to connect to this cluster.
You can enroll your account into multifactor authentication on this page:
https://ccdb.alliancecan.ca/multi_factor_authentications
by following the instructions available here:
https://docs.alliancecan.ca/wiki/Multifactor_authentication
=============================================================================
L'authentification multifacteur est maintenant obligatoire pour vous connecter
à cette grappe. Configurez votre compte sur
https://ccdb.alliancecan.ca/multi_factor_authentications
et suivez les directives dans
https://docs.alliancecan.ca/wiki/Multifactor_authentication/fr.
Password:
Note that the LC_ALL=C above is to avoid the following warnings in
R, which happen on my system hat has several LC_* environment
variables set to fr_FR.UTF-8:
During startup - Warning messages:
1: Setting LC_TIME failed, using "C"
2: Setting LC_MONETARY failed, using "C"
3: Setting LC_PAPER failed, using "C"
4: Setting LC_MEASUREMENT failed, using "C"
After you put in the correct password, you get the prompt below, which means you need to do two-factor authentication,
Duo two-factor login for thocking
Enter a passcode or select one of the following options:
1. Duo Push to iphone (iOS)
Passcode or option (1-1):
So at this point you can either
- go into your telephone, Duo Mobile app, Digital Research Alliance of Canada, Show Passcode. You should get a six digit number that you can type at the prompt to login.
- or type 1 at the prompt, and then go into your Duo Mobile app, tap accept (green check mark).
Then we get the following prompt
Success. Logging you in...
Last failed login: Tue Jul 16 22:44:50 EDT 2024 from 70.81.139.71 on ssh:notty
There were 5 failed login attempts since the last successful login.
Last login: Tue Jun 25 13:30:36 2024 from 132.210.204.231
################################################################################
__ __ ____ _
| \/ |_ __|___ \| |__ Bienvenue sur Mammouth-Mp2b / Welcome to Mammoth-Mp2b
| |\/| | '_ \ __) | '_ \
| | | | |_) / __/| |_) | Aide/Support: mammouth@calculcanada.ca
|_| |_| .__/_____|_.__/ Globus endpoint: computecanada#mammouth
|_| Documentation: docs.calculcanada.ca
docs.calculcanada.ca/wiki/Mp2
Grappe avec le meme environnement d'utilisation que Cedar et Graham (Slurm scheduler).
Cluster with the same user environment as Cedar and Graham (Slurm scheduler).
________________________________________________________________________________
| | Slurm | Slurm | Slurm
Mp2b | Memory/Cores | --nodes | --mem | --cpus-per-task
nodetype | | max | max | max
----------+-------------------------------+---------+---------+-----------------
base | 31 GB memory, 24 cores/node | 1588 | 31G | 24
large | 251 GB memory, 48 cores/node | 20 | 251G | 48
xlarge | 503 GB memory, 48 cores/node | 2 | 503G | 48
__________|_______________________________|_________|_________|_________________
2018-05-16 Slurm --mem option
15:19 ==================
SVP specifier la memoire requise par noeud avec l'option --mem a la soumission de
tache (256 Mo par coeur par defaut). Maximum --mem=31G pour les noeuds de base.
Please specify the required memory by node with the --mem option at job
submission (256 MB per core by default). Maximum --mem=31G for base nodes.
2018-12-19 PAS de sauvegarde de fichiers sur scratch et project sur Mammouth
14:09 NO file backup on scratch and project on Mammoth
=================================================================
Nous vous recommandons d'avoir une seconde copie de vos fichiers importants
ailleurs par mesure de precaution.
We recommend that you have a second copy of your important files elsewhere as
a precaution.
2024-06-04 Repertoire $SCRATCH non-disponible / $SCRATCH directory not available
11:58 =====================================================================
Problème materiel sur une des serveurs MDS de $SCRATCH.
Hardware issue with one of the MDS of $SCRATCH.
###############################################################################
[thocking@ip15-mp2 ~]$
git and github configuration
We want to be able to git push to github from mammouth, so first we need to create a key. Make sure to use a passphrase that is unique, and only you will be able to figure out. It says you can leave it empty for no passphrase, but please don’t do that, because it is very insecure (anyone who can make a copy of your id_rsa file can impersonate you).
[thocking@ip15-mp2 ~]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/thocking/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/thocking/.ssh/id_rsa.
Your public key has been saved in /home/thocking/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:eV/C+QbTrgyCx+wCmmj7QTopsEXoNxMTXhWkH6QPQqE thocking@ip15.m
The key's randomart image is:
+---[RSA 2048]----+
| +..o=. |
| .+ o + |
|.E.= + . |
|.. + + .. . o |
|...= oS . * o |
|.o= + + . . B |
|o= + .. = . . + |
|o.+ . .o . o o |
|..o. .. o |
+----[SHA256]-----+
[thocking@ip15-mp2 ~]$ cat .ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCx+7vcg76d5Px+b78KOrG9Dg3Qw4KQL45DeG7055mhEjuLsBK9s4MQCl7ij1N3Wne7MeGbFbWYceqexeAVheLehKrJ/38lIITNk9skl+jlTc6X8NVlkTvoOGbrjqR45abvrpSjDX6ID3Lk9/8oBXLfBCgx4NuCTsRJYobzZWGbmH4mBvied4fz+yE2Mz5chx2SMe2i2Nll2FCPb9qm3LZoX+lsCiGAtZvpNEPA9qfxQwfkZ/H/6HY65PVvgEe0+eicdOFoTgs+lkW4YoMw2+iZQcsIwJ7ZvBKcBEw3bBOvXhENI9MKXSaNCiRH24lFEE2ArmYD+nCLeIjdT92AnP/N thocking@ip15.m
Then go to GitHub, Settings, SSH and GPG keys, Title: Mammouth, Key type: Authentication Key, Key: all the text from your version of the cat command above.
Then when you run git commands from Mammouth, which pull/push from github, it will ask you for your RSA key passphrase.
[thocking@ip15-mp2 ~]$ git clone git@github.com:tdhock/dotfiles
Cloning into 'dotfiles'...
Warning: Permanently added the ECDSA host key for IP address '140.82.114.4' to the list of known hosts.
Enter passphrase for key '/home/thocking/.ssh/id_rsa':
Enter passphrase for key '/home/thocking/.ssh/id_rsa':
remote: Enumerating objects: 266, done.
remote: Counting objects: 100% (48/48), done.
remote: Compressing objects: 100% (32/32), done.
remote: Total 266 (delta 27), reused 37 (delta 16), pack-reused 218
Receiving objects: 100% (266/266), 59.87 KiB | 666.00 KiB/s, done.
Resolving deltas: 100% (162/162), done.
emacs
For text editing, I recommend running emacs in either a terminal via
emacs -nw (nw means no window),
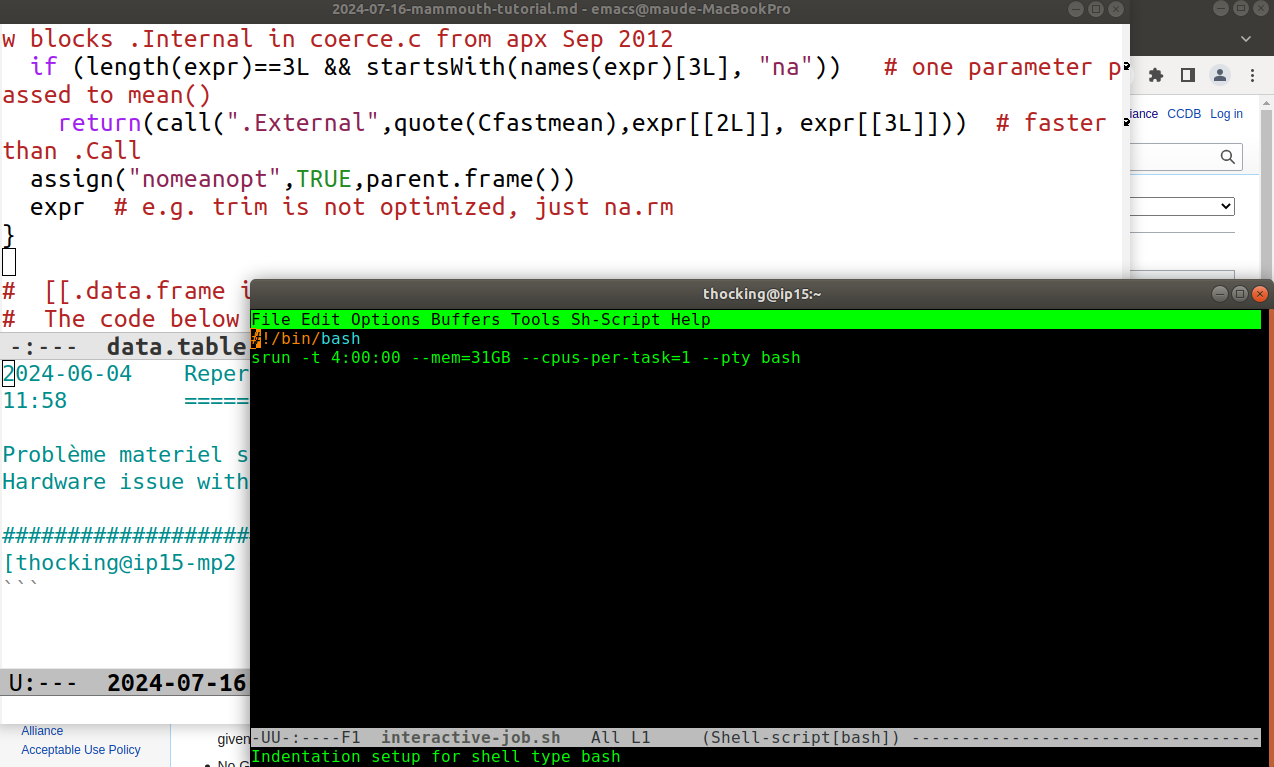
In the screenshot above, I ran emacs -nw ~/bin/interactive-job.sh in
the lower right terminal (black and green), which opens that shell
script for editing in emacs (running on mammouth). To suspend this
emacs running in the terminal, you can type Control-Z to get back to
the shell prompt, then you can use the fg command to get back to
emacs. Note that there is another emacs running on my local laptop
computer, in the upper left of the screen.
On a fast internet connection, I prefer running emacs in an X11 window (more convenient but maybe slower response times),
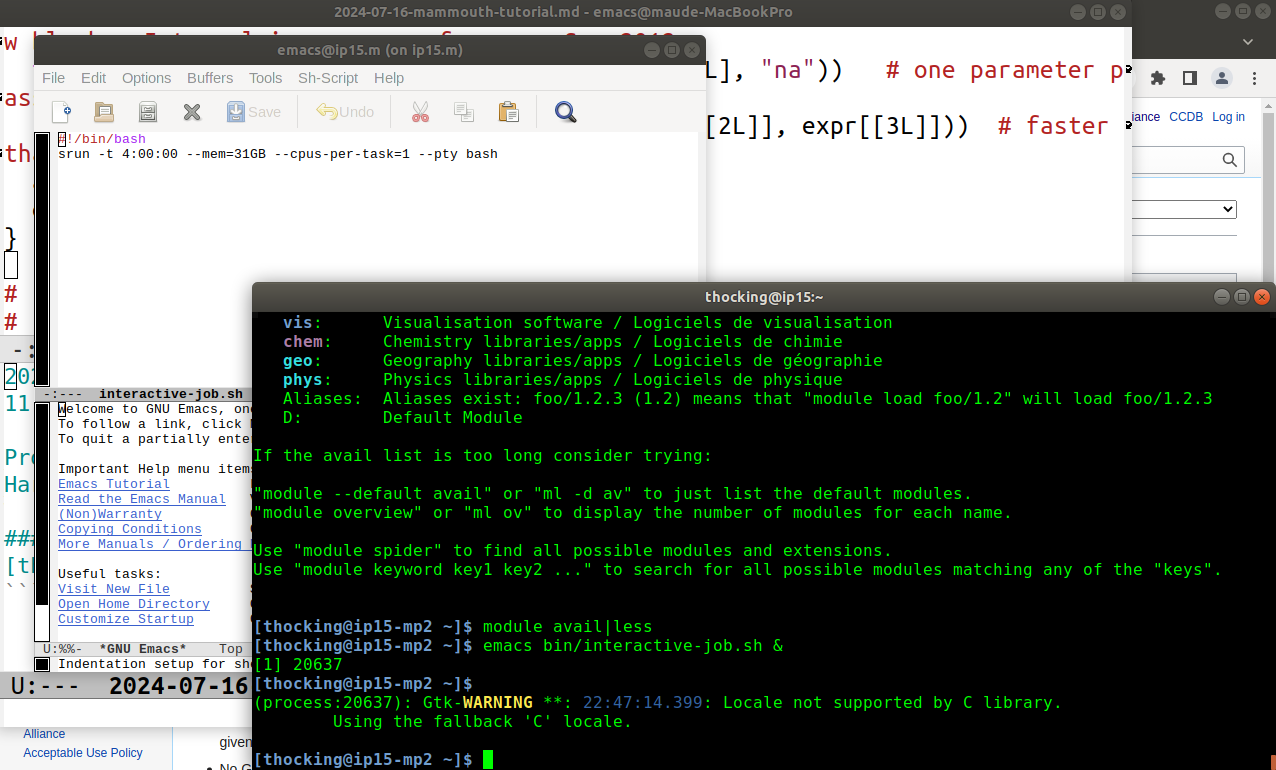
In the screenshot above, I ran emacs ~/bin/interactive-job.sh & in
the terminal. The ampersand / and sign & means to run the command in
the background (do not wait for it to finish before giving the next
prompt), and then a new X11 window pops up running emacs. You can use
the window name (in emacs language, that is a frame title) to
differentiate the two emacs instances:
emacs@ip15.m (on ip15.m)is on Mammouth.emacs@maude-MacBookProis on my local laptop computer.
To configure emacs support for R, you can follow my instructions here. The most important is to first add MELPA
(require 'package)
(add-to-list 'package-archives
'("melpa" . "https://melpa.org/packages/") t)
Then install ess package. Other packages which may be useful:
poly-Rfor editing Rmd,quarto-modefor editing qmd,markdown-modefor editing md,elpyfor interactive python execution/help/etc.
modules including R
Now if you run M-x R RET in emacs (type x while holding down
alt/option, then type R, then type return/enter), you should get an R
not found error. That is because R is not on the path by
default. Mammouth uses the module command to add non-essential
programs to the path (git and emacs are there by default, no module
needed). To list the available modules,
[thocking@ip15-mp2 ~]$ module avail
-------------------------- MPI-dependent sse3 modules --------------------------
elpa/2020.05.001 (math) mpi4py/3.0.3 (t) quantumespresso/6.6 (chem)
hdf5-mpi/1.10.6 (io) mpi4py/3.1.3 (t,D)
----------------------- Compiler-dependent sse3 modules ------------------------
beef/0.1.1 (chem) hdf5/1.10.6 (io) openblas/0.3.17 (math)
blis/0.8.1 (L) libxc/4.3.4 (chem) openmpi/4.0.3 (L,m)
flexiblas/3.0.4 (L,D) ntl/11.4.3 (math) samstat/1.5.1
--------------------------------- Core Modules ---------------------------------
abaqus/2021 (phys)
actc/1.1
...
quantumatk/2019.12
r/4.1.0 (t)
r/4.2.1 (t,D)
racon/1.4.13 (bio)
...
xmlf90/1.5.4 (t)
xtensor/0.24.2
-------------------------------- Custom modules --------------------------------
apptainer-suid/1.1 gentoo/2023 (S) StdEnv/2020 (S,L,D)
arch/sse3 nixpkgs/16.09 (S) StdEnv/2023 (S)
CCconfig (L) StdEnv/2016.4 (S)
gentoo/2020 (S,L,D) StdEnv/2018.3 (S)
Where:
S: Module is Sticky, requires --force to unload or purge
bio: Bioinformatic libraries/apps / Logiciels de bioinformatique
m: MPI implementations / Implémentations MPI
math: Mathematical libraries / Bibliothèques mathématiques
L: Module is loaded
io: Input/output software / Logiciel d'écriture/lecture
t: Tools for development / Outils de développement
vis: Visualisation software / Logiciels de visualisation
chem: Chemistry libraries/apps / Logiciels de chimie
geo: Geography libraries/apps / Logiciels de géographie
phys: Physics libraries/apps / Logiciels de physique
Aliases: Aliases exist: foo/1.2.3 (1.2) means that "module load foo/1.2" will load foo/1.2.3
D: Default Module
If the avail list is too long consider trying:
"module --default avail" or "ml -d av" to just list the default modules.
"module overview" or "ml ov" to display the number of modules for each name.
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching
any of the "keys".
[thocking@ip15-mp2 ~]$
The important module line for R is
r/4.2.1 (t,D)
where t means Tools for development and D means Default
Module. Since it is default, we don’t need to specify the slash and
version number suffix, and we can just quit emacs and then do
[thocking@ip15-mp2 ~]$ which R
/usr/bin/which: no R in (/home/thocking/bin:/opt/software/slurm/bin:/cvmfs/soft.computecanada.ca/easybuild/software/2020/Core/mii/1.1.2/bin:/cvmfs/soft.computecanada.ca/easybuild/software/2020/sse3/Compiler/intel2020/flexiblas/3.0.4/bin:/cvmfs/soft.computecanada.ca/easybuild/software/2020/sse3/Compiler/intel2020/openmpi/4.0.3/bin:/cvmfs/soft.computecanada.ca/easybuild/software/2020/sse3/Core/libfabric/1.10.1/bin:/cvmfs/soft.computecanada.ca/easybuild/software/2020/sse3/Core/ucx/1.8.0/bin:/cvmfs/restricted.computecanada.ca/easybuild/software/2020/Core/intel/2020.1.217/compilers_and_libraries_2020.1.217/linux/bin/intel64:/cvmfs/soft.computecanada.ca/easybuild/software/2020/Core/gcccore/9.3.0/bin:/cvmfs/soft.computecanada.ca/easybuild/bin:/cvmfs/soft.computecanada.ca/custom/bin:/cvmfs/soft.computecanada.ca/gentoo/2020/usr/sbin:/cvmfs/soft.computecanada.ca/gentoo/2020/usr/bin:/cvmfs/soft.computecanada.ca/gentoo/2020/sbin:/cvmfs/soft.computecanada.ca/gentoo/2020/bin:/cvmfs/soft.computecanada.ca/custom/bin/computecanada:/opt/software/slurm/bin:/opt/software/bqtools/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/puppetlabs/bin:/home/thocking/.local/bin:/home/thocking/bin)
[thocking@ip15-mp2 ~]$ module load r
[thocking@ip15-mp2 ~]$ which R
/cvmfs/soft.computecanada.ca/easybuild/software/2020/sse3/Core/r/4.2.1/bin/R
[thocking@ip15-mp2 ~]$ R --version
R version 4.2.1 (2022-06-23) -- "Funny-Looking Kid"
Copyright (C) 2022 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under the terms of the
GNU General Public License versions 2 or 3.
For more information about these matters see
https://www.gnu.org/licenses/.
Now you can open emacs again, M-x R to open an R terminal (you have
to press enter/return as above, but typically this is omitted when
describing M-x commands), or open some_file.R and use C-RET (type
return/enter while holding down control).
Before installing R packages, make sure to declare a CRAN mirror in your ~/.Rprofile:
options(repos=c(CRAN="http://cloud.r-project.org"))
RStudio web connected to cluster
What if you don’t want to learn emacs? A reasonable alternative is RStudio, which can be run in a web browser, connected to the Alliance Canada clusters.
Start by going to JupyterHub on clusters, and follow a link to jupyterhub on one of the clusters, for example JHubOnBeluga.
- After logging in to that page using your Alliance Canada credentials, you need to specify how much time and memory you want for the compute node job which your RStudio will use for executing R/shell/etc code.
- Default of 1 hour should be reasonable if you just want to launch a job, or gather results.
- Try increasing time limit to 8 hours if you want to have a RStudio open on the cluster for a full day of work/testing.
- You may need to increase memory if you are launching a large experiment, or gathering a lot of results. Try 8000 MB for MNIST.
- Before JupyterHub opens, you will have to wait for the cluster to queue and launch your job.

The screenshot above shows the jupyterhub window, from which you can launch RStudio.
- First click hexagon/Softwares on left.
- Then type
rstudioin the text field above LOADED MODULES, which uses the text you enter to limit the display of AVAILABLE MODULES. - Click on grey
Loadbutton which appears when you hover the pointer over the most recent version ofrstudio-server(version 4.4 in the screenshot above). - Click RStudio (R icon in a blue circle) to open a new tab running RStudio.
- The RStudio will be running on a compute node, which typically will not have internet access, so
install.packages()will not work.
To install packages, you should
- open a terminal, and ssh to the same cluster (for example
beluga.calculcanada.ca), which will get you to a login node (with internet access). - then do
module load r/4.4.1or similar (make sure the version number is consistent with the RStudio version you selected in the web browser). - then run
R -e 'install.packages("mlr3")'or similar to download the data/code you need. - you can run
.libPaths()orsystem.file(package="mlr3")in both versions of R (in terminal/login node, and on web/compute node), to verify that you are installing packages to the same library.
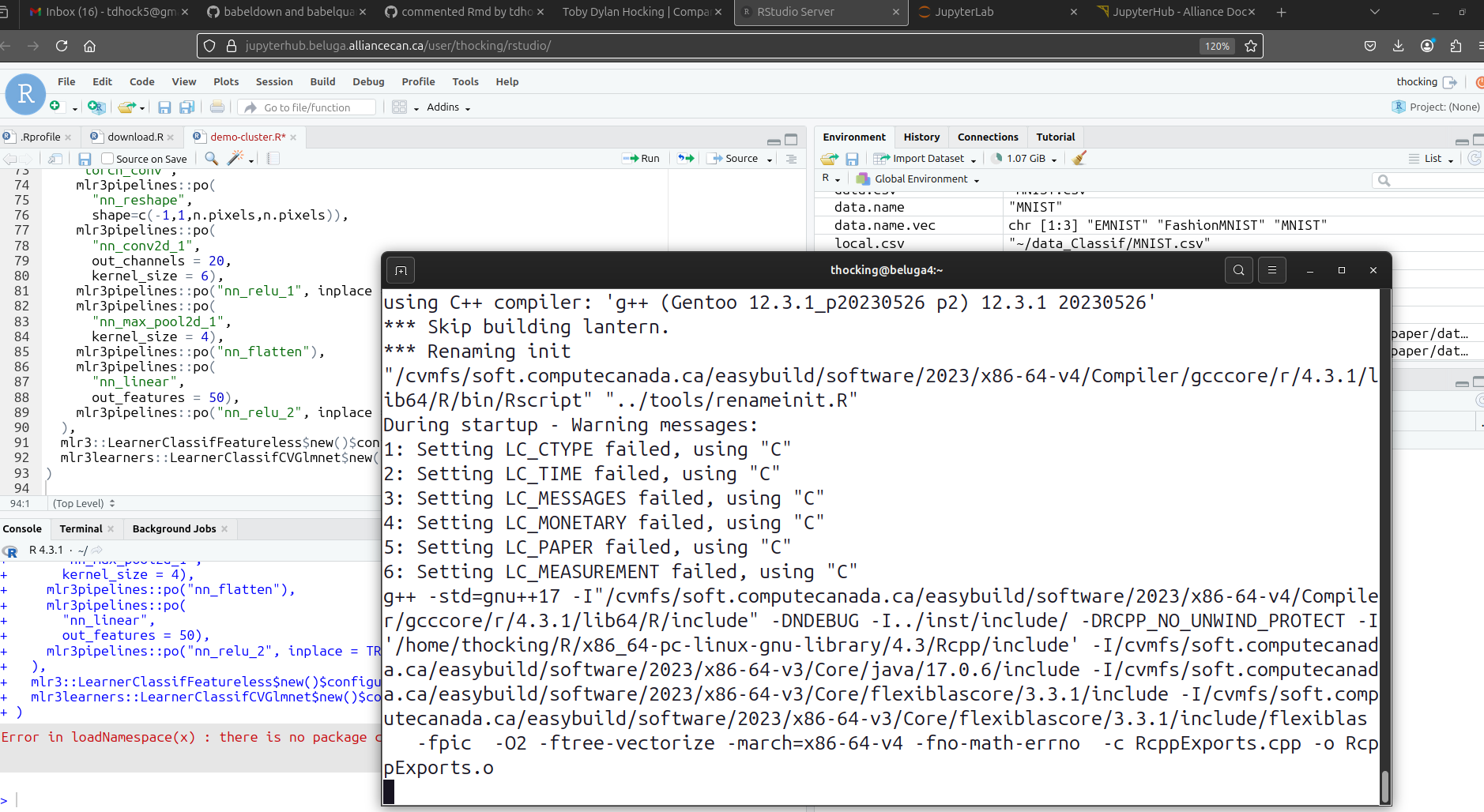
The result should look something like below, which is a screenshot of RStudio in a web browser window (connected to a beluga compute node), and R installing packages from a terminal window (connected to a beluga login node).
VS Code
Similar to RStudio setup described in the last section, there is support for VS Code, as described in the docs.
- load module
code-serverandr/4.3.1
Microsoft R for VS Code Docs say to install.packages("languageserver") (in a terminal ssh to login node).
To install the R VS Code extension, first use a terminal to ssh to a login node, and download the extension via
wget https://openvsxorg.blob.core.windows.net/resources/REditorSupport/r/2.8.6/REditorSupport.r-2.8.6.vsix
Extensions icon on left (four squares; upper right one diagonal), ... button, Install from VSIX -> It should install but I get an error message that the extentions directory is not writable: “Extract: ENOENT: no such file or directory, mkdir ‘/cvmfs/soft.computecanada.ca/easybuild/software/2023/x86-64-v3/Core/code-server/4.101.2/extensions/.95873ba9-66e2-46f4-a327-874b4aa8eced’”.
Microsoft docs for VS code command line interface.
Alliance Canada docs for running VS Code on your computer.
https://github.com/microsoft/vscode-docs/pull/8321/files
Non-working R versions
Other options for adding R modules:
[thocking@ip15-mp2 ~]$ R --version
[mii] Please select a module to run R:
MODULE PARENT(S)
1 r/4.2.1 StdEnv/2020
2 r/4.1.0 StdEnv/2020
3 r/4.4.0 StdEnv/2023
4 r/4.3.1 StdEnv/2023
Make a selection (1-4, q aborts) [1]: 3
[mii] loading StdEnv/2023 r/4.4.0 ...
Lmod has detected the following error: The StdEnv/2023 environment is not available for
architecture sse3.
While processing the following module(s):
Module fullname Module Filename
--------------- ---------------
gentoo/2023 /cvmfs/soft.computecanada.ca/custom/modules/gentoo/2023.lua
StdEnv/2023 /cvmfs/soft.computecanada.ca/custom/modules/StdEnv/2023.lua
-bash: R: command not found
but we get an error message above “environment is not available for architecture sse3” which refers to SSE3 (2004), a specific kind of intel CPU instructions used by the Mammouth computers. According to Éric Giguère, eric.giguere@calculquebec.ca
StdEnv/2023 and more recent R versions apparently only work with newer CPUs, AVX2 (2013) and AVX-512 (2015), which are not present on Monsoon, but which are present on Narval and Beluga.
shell configuration
I put the following in ~/.bashrc which is run every time you start a new shell.
export PATH=$HOME/bin:$PATH
export EDITOR="emacs -nw"
Node types
MP2 docs under Site-specific policies says “Each job must have a duration of at least one hour (at least five minutes for test jobs) and a user cannot have more than 1000 jobs (running and queued) at any given time. The maximum duration of a job is 168 hours (seven days).” and under Node characteristics it says there are three node types.
node.type.txt <- "Quantity Cores Available Memory CPU Type Storage GPU Type
1588 24 31 GB or 31744 MB 12 cores/socket, 2 sockets/node. AMD Opteron Processor 6172 @ 2.1 GHz 1TB SATA disk. -
20 48 251 GB or 257024 MB 12 cores/socket, 4 sockets/node. AMD Opteron Processor 6174 @ 2.2 GHz 1TB SATA disk. -
2 48 503 GB or 515072 MB 12 cores/socket, 4 sockets/node. AMD Opteron Processor 6174 @ 2.2 GHz 1TB SATA disk. -"
(node.type.dt <- data.table::fread(node.type.txt)[, .(
Nodes=Quantity,
Cores_per_node=Cores,
`Available Memory`
)][
, Total_cores := Nodes*Cores_per_node
][])
## Nodes Cores_per_node Available Memory Total_cores
## <int> <int> <char> <int>
## 1: 1588 24 31 GB or 31744 MB 38112
## 2: 20 48 251 GB or 257024 MB 960
## 3: 2 48 503 GB or 515072 MB 96
The output above says there are 1,588 nodes with 24 cores per node and 31 GB of memory, for a total number of 38,112 cores. Those are the compute resources which could be made available, but since Mammouth is near end of service, there are not many users, and so the admins have turned off a large number of nodes, in order to conserve electricity. To find out the actual number of nodes available, below we count nodes in each state/partition.
> node.txt <- system("sinfo -N",intern=TRUE)
> (node.dt <- data.table::fread(text=node.txt))
NODELIST NODES PARTITION STATE
<char> <int> <char> <char>
1: cp0101 1 cpubase_b3 down*
2: cp0101 1 cpubase_b1 down*
3: cp0101 1 cpubase_b2 down*
4: cp0101 1 cpubase_interac down*
5: cp0102 1 cpubase_b3 down*
---
6115: cp3706 1 c-royer mix
6116: cp3706 1 c-iq mix
6117: cp3707 1 c-blais mix
6118: cp3707 1 c-kerrcat mix
6119: cp3708 1 c-tremblay mix
> dcast(node.dt, PARTITION ~ STATE, sum, value.var="NODES")
Key: <PARTITION>
PARTITION alloc down* drain drain* fail* idle mix
<char> <int> <int> <int> <int> <int> <int> <int>
1: c-apc 0 0 0 0 0 2 2
2: c-aphex 0 0 1 0 0 0 0
3: c-blais 0 0 0 0 0 0 1
4: c-ctabrp 0 90 0 18 0 0 0
5: c-fat3072 0 0 0 0 0 1 0
6: c-iq 2 0 0 0 0 0 3
7: c-kerrcat 0 0 0 0 0 0 1
8: c-royer 0 0 0 0 0 0 1
9: c-tremblay 0 0 0 0 0 0 1
10: cpubase_b1 73 34 14 1275 41 35 4
11: cpubase_b2 73 34 14 1275 41 35 4
12: cpubase_b3 73 34 14 1275 41 35 4
13: cpubase_interac 73 34 14 1275 41 35 4
14: cpularge_b1 19 0 0 1 0 2 0
15: cpularge_b2 19 0 0 1 0 0 0
16: cpularge_b3 19 0 0 1 0 0 0
17: cpularge_interac 19 0 0 1 0 2 0
18: cpuxlarge_b1 0 0 0 0 0 2 0
19: cpuxlarge_b2 0 0 0 0 0 2 0
20: cpuxlarge_b3 0 0 0 0 0 2 0
21: cpuxlarge_interac 0 0 0 0 0 2 0
PARTITION alloc down* drain drain* fail* idle mix
From https://slurm.schedmd.com/sinfo.html
- DRAINED means “The node is unavailable for use per system administrator request.”
*is described under NODE STATE CODES means “The node is presently not responding and will not be allocated any new work.”CPUS(A/I/O/T)means “allocated/idle/other/total”- “number of sockets, cores, threads (S:C:T)”
or summarized below,
[thocking@ip15-mp2 ~]$ sinfo -s |grep 'base_i\|NODE'
PARTITION AVAIL TIMELIMIT NODES(A/I/O/T) NODELIST
cpubase_interac up 3:00:00 55/57/1364/1476 cp[0101-0168,0201-0272,0303-0358,0501-0532,0601-0676,0701-0768,0801-0872,0901-0956,1001-1072,1101-1168,1401-1432,1437-1468,1501-1572,1601-1668,1701-1772,1801-1868,1901-1972,2001-2068,2101-2172,2201-2268,2301-2372,2401-2468,2501-2572]
So the output above indicates there are about 100 nodes available (A=alloc/ated or I=idle). There are 1364 O=Other nodes (drain) which are powered off. The total 1476 does not add up to the 1588 listed on Node characteristics, because when nodes break, they are removed.
To find out the number of CPUs available we can use the R code below on Mammouth
library(data.table)
node.txt <- system("sinfo -N --format=%all",intern=TRUE)
node.dt <- fread(text=node.txt)
int <- function(name)list(nc::group(name, "[0-9]+", as.integer), "/?")
measure.vars <- c("allocated","idle","other","total")
CPUS.pattern <- lapply(measure.vars, int)
cpu.counts.wide <- nc::capture_first_df(
node.dt, "CPUS(A/I/O/T)"=CPUS.pattern, existing.error=FALSE)
cpu.counts.long <- melt(
cpu.counts.wide,
measure.vars=measure.vars,
id.vars=c("PARTITION","NODELIST"),
variable.name="state",
value.name="cpus")
dcast(cpu.counts.long, PARTITION ~ state, sum, value.var="cpus")
The code above gave me the output below
> dcast(cpu.counts.long, PARTITION ~ state, sum, value.var="cpus")
Key: <PARTITION>
PARTITION allocated idle other total
<char> <int> <int> <int> <int>
1: c-apc 56 200 0 256
2: c-aphex 0 0 48 48
3: c-blais 128 0 0 128
4: c-ctabrp 0 0 2592 2592
5: c-fat3072 0 144 0 144
6: c-iq 339 125 0 464
7: c-kerrcat 128 0 0 128
8: c-royer 64 64 0 128
9: c-tremblay 128 384 0 512
10: cpubase_b1 1832 856 32736 35424
11: cpubase_b2 1832 856 32736 35424
12: cpubase_b3 1832 856 32736 35424
13: cpubase_interac 1832 856 32736 35424
14: cpularge_b1 912 96 48 1056
15: cpularge_b2 912 0 48 960
16: cpularge_b3 912 0 48 960
17: cpularge_interac 912 96 48 1056
18: cpuxlarge_b1 0 96 0 96
19: cpuxlarge_b2 0 96 0 96
20: cpuxlarge_b3 0 96 0 96
21: cpuxlarge_interac 0 96 0 96
PARTITION allocated idle other total
which indicates there are 856 idle CPUs in the cpubase partitions. Admins have told me that if there is a queue, then more nodes could be powered back on. However, Site-specific policies says “a user cannot have more than 1000 jobs (running and queued) at any given time.”
srun
Instead of running compute intensive code on the login node, you should try running it in an Interactive job, via the code below
[thocking@ip15-mp2 ~]$ srun -t 4:00:00 --mem=31GB --cpus-per-task=1 --pty bash
srun: error: Unable to allocate resources: Requested time limit is invalid (missing or exceeds some limit)
[thocking@ip15-mp2 ~]$ srun -t 2:00:00 --mem=31GB --cpus-per-task=1 --pty bash
[thocking@cp2554 ~]$
Note the output above indicates that 4h time limit is invalid for the interactive job, but 2h time limit works fine. Admins told me the max time limit for interactive jobs is 3h, but they also said that limits could be changed on Mammouth if necessary.
Q&A
Does torch work?
torch in R does not seem to work on Mammouth. I got floating point exceptions when installing from CRAN, and link errors when installing binaries from a CDN. However I got torch in R to work on Beluga by installing from CRAN.
Which partition to use?
The scheduler will choose a partition for you, based on the amount of time and memory you request.
It will be one of the following. There are 3 types of nodes on the docs. On “sinfo” I see cpuSIZE_TYPE where
SIZE=base, large, xlarge
TYPE=interac, b1, b2, b3
SIZE determines memory, type determines type of job and time limit.
is conda allowed?
Yes, based on an email from sys admins, who said that Mammouth is no longer officially supported, so they do not plan to respond to software install requests there, and so we can install any research software we want.
how does the schedular work?
Job scheduling policies, Backfilling explains that
def-accounts all have the same target usage (NormShares)- If you have not used (EffectvUsage) as much as your target, you will have larger priority (FairShare)
- Backfilling means to start lower priority jobs as long as they will not delay any higher priority jobs, so you can use more compute time if nodes are available, as long as other people with higher priority are not asking for them.
> sshare.dt <- data.table::fread(cmd="sshare -P")
> sshare.dt[RawShares>1][order(-EffectvUsage)][1:30, .(Account,RawShares,NormShares,RawUsage,EffectvUsage)]
Account RawShares NormShares RawUsage EffectvUsage
<char> <int> <num> <int> <num>
1: def-ko1_cpu 39168 0.004348 623692294 0.328009
2: def-ilafores_cpu 39168 0.004348 410827831 0.216061
3: def-harveypi_cpu 39168 0.004348 323894911 0.170341
4: def-legaultc_cpu 39168 0.004348 303479972 0.159604
5: def-dahai_cpu 39168 0.004348 82894351 0.043595
6: def-hykee_cpu 39168 0.004348 52042825 0.027370
7: def-dsenech_cpu 39168 0.004348 41381159 0.021763
8: def-blaisale_cpu 39168 0.004348 32295489 0.016985
9: def-xroucou_cpu 39168 0.004348 21903675 0.011519
10: def-hofheinz_cpu 39168 0.004348 4039137 0.002124
11: def-larissa1_cpu 39168 0.004348 3086935 0.001623
12: def-solderaa_cpu 39168 0.004348 624755 0.000329
13: def-descotea_cpu 39168 0.004348 428423 0.000225
14: def-tremblay_cpu 39168 0.004348 389762 0.000205
15: def-soltani7_cpu 39168 0.004348 248950 0.000131
16: def-royb1501_cpu 39168 0.004348 136803 0.000072
17: def-subilan_cpu 39168 0.004348 52156 0.000027
18: def-frechett_cpu 39168 0.004348 10973 0.000006
19: def-marie87_cpu 39168 0.004348 9258 0.000005
20: def-labolcf_cpu 39168 0.004348 4310 0.000002
21: def-jacquesp_cpu 39168 0.004348 2417 0.000001
22: def-luhuizho_cpu 39168 0.004348 1752 0.000001
23: def-aacohen_cpu 39168 0.004348 0 0.000000
24: def-abandrau_cpu 39168 0.004348 0 0.000000
25: def-abds2502_cpu 39168 0.004348 0 0.000000
26: def-afrigon_cpu 39168 0.004348 0 0.000000
27: def-alang_cpu 39168 0.004348 0 0.000000
28: def-alewin_cpu 39168 0.004348 0 0.000000
29: def-allh1901_cpu 39168 0.004348 0 0.000000
30: def-amob2301_cpu 39168 0.004348 0 0.000000
Account RawShares NormShares RawUsage EffectvUsage
> sshare.dt[grep("thocking",Account), .(Account,RawShares,NormShares,RawUsage,EffectvUsage)]
Account RawShares NormShares RawUsage EffectvUsage
<char> <int> <num> <int> <num>
1: def-thocking_cpu 39168 0.004348 10 0
2: def-thocking_cpu 1 1.000000 10 1
The output above shows that there are 22 groups who have used any compute time at all. I have not yet.
Conclusions
We have shown how to connect to Mammouth, and to setup some basic software. Exercise for the reader: go to my blog, search for a post about “monsoon” which is the super-computer at Northern Arizona University, and see if you can do the same computations on Mammouth.
- Cross-validation experiments using R/mlr3batchmark
- Cross-validation experiments using python/slurm command line programs
Exercise 2: run sinfo on
Narval and
Beluga
or other National Systems
to see the
number of allocated/idle nodes. Which cluster has more total nodes?
More nodes idle?
Below Mammouth at UdeS
[thocking@ip15-mp2 ~]$ sinfo -s -o "%P %C"
PARTITION CPUS(A/I/O/T)
cpubase_b3 254/2122/33048/35424
cpubase_b2 254/2122/33048/35424
cpubase_b1 254/2122/33048/35424
cpubase_interac 254/2122/33048/35424
cpularge_b3 64/848/48/960
cpularge_b2 64/848/48/960
cpularge_b1 64/944/48/1056
cpularge_interac 64/944/48/1056
cpuxlarge_b3 0/96/0/96
cpuxlarge_b2 0/96/0/96
cpuxlarge_b1 0/96/0/96
cpuxlarge_interac 0/96/0/96
c-fat3072 0/144/0/144
c-ctabrp 0/0/2592/2592
c-apc 8/248/0/256
c-aphex 1/47/0/48
c-royer 48/80/0/128
c-blais 0/128/0/128
c-kerrcat 0/128/0/128
c-tremblay 128/384/0/512
c-iq 308/156/0/464
Below Monsoon at NAU
th798@wind:~$ sinfo -s -o "%P %C"
PARTITION CPUS(A/I/O/T)
core* 783/3053/84/3920
gpu 20/124/28/172
Below Narval at ETS
[thocking@narval3 ~]$ sinfo -s -o "%P %C"
PARTITION CPUS(A/I/O/T)
cpubase_interac 40322/4846/2448/47616
cpubase_bynode_b1 65215/7897/5416/78528
cpubase_bynode_b2 63093/6755/5352/75200
cpubase_bynode_b3 63093/6755/5352/75200
cpubase_bynode_b4 60117/6275/5224/71616
cpubase_bynode_b5 57687/5514/4831/68032
cpubase_bycore_b1 32461/3979/4712/41152
cpubase_bycore_b2 32461/3979/4712/41152
cpubase_bycore_b3 32461/3979/4712/41152
cpubase_bycore_b4 32461/3979/4712/41152
cpubase_bycore_b5 25693/2083/3136/30912
cpularge_interac 1386/518/272/2176
cpularge_bynode_b1 1528/504/272/2304
cpularge_bynode_b2 1528/504/272/2304
cpularge_bynode_b3 1492/476/272/2240
cpularge_bynode_b4 1492/476/272/2240
cpularge_bynode_b5 1472/432/272/2176
cpularge_bycore_b1 1144/504/272/1920
cpularge_bycore_b2 1144/504/272/1920
cpularge_bycore_b3 1108/476/272/1856
cpularge_bycore_b4 1088/432/272/1792
cpularge_bycore_b5 1044/412/272/1728
gpubase_interac 2679/1604/149/4432
gpubase_bynode_b1 5358/2266/408/8032
gpubase_bynode_b2 5358/2266/408/8032
gpubase_bynode_b3 5280/2248/408/7936
gpubase_bynode_b4 5212/2220/408/7840
gpubase_bynode_b5 4092/1802/362/6256
gpubase_bygpu_b1 4643/2453/408/7504
gpubase_bygpu_b2 4643/2453/408/7504
gpubase_bygpu_b3 4565/2435/408/7408
gpubase_bygpu_b4 4497/2407/408/7312
gpubase_bygpu_b5 3377/1989/362/5728
cpubackfill 32158/4276/3758/40192
gpubackfill 1783/1348/149/3280
c-frigon 2122/1142/64/3328
Below Beluga at ETS
[thocking@beluga1 ~]$ sinfo -s -o "%P %C"
PARTITION CPUS(A/I/O/T)
cpubase_interac 8114/1046/120/9280
cpubase_bynode_b1 26710/2850/360/29920
cpubase_bynode_b2 26486/2674/320/29480
cpubase_bynode_b3 24846/2594/280/27720
cpubase_bynode_b4 23166/2554/240/25960
cpubase_bynode_b5 20330/1870/240/22440
cpubase_bycore_b1 13658/2222/280/16160
cpubase_bycore_b2 13434/2046/240/15720
cpubase_bycore_b3 12246/1474/240/13960
cpubase_bycore_b4 12246/1474/240/13960
cpubase_bycore_b5 12133/1427/240/13800
cpularge_interac 503/297/0/800
cpularge_bynode_b1 1224/896/0/2120
cpularge_bynode_b2 1224/856/0/2080
cpularge_bynode_b3 1184/856/0/2040
cpularge_bynode_b4 1064/856/0/1920
cpularge_bynode_b5 984/856/0/1840
cpularge_bycore_b1 864/856/0/1720
cpularge_bycore_b2 864/856/0/1720
cpularge_bycore_b3 824/856/0/1680
cpularge_bycore_b4 801/839/0/1640
cpularge_bycore_b5 791/809/0/1600
gpubase_interac 2389/2903/108/5400
gpubase_bynode_b1 3005/3767/108/6880
gpubase_bynode_b2 2968/3444/108/6520
gpubase_bynode_b3 2968/3444/108/6520
gpubase_bynode_b4 2968/3444/108/6520
gpubase_bynode_b5 474/646/0/1120
gpubase_bygpu_b1 2393/3019/68/5480
gpubase_bygpu_b2 2356/3016/68/5440
gpubase_bygpu_b3 2316/3016/68/5400
gpubase_bygpu_b4 1832/2780/68/4680
gpubase_bygpu_b5 434/646/0/1080
cpubackfill 5470/1210/200/6880
gpubackfill 434/646/0/1080
Below Cedar at SFU
[thocking@cedar1 ~]$ sinfo -s -o "%P %C"
PARTITION CPUS(A/I/O/T)
cpubase_bycore_b6 17251/461/1552/19264
cpubase_bycore_b5 27723/741/2768/31232
cpubase_bycore_b4 37601/1711/3776/43088
cpubase_bycore_b3 43895/3099/4238/51232
cpubase_bycore_b2 52308/3382/5622/61312
cpubase_bycore_b1 52308/3382/5622/61312
cpubase_bynode_b6 17251/461/1552/19264
cpubase_bynode_b5 27723/741/2768/31232
cpubase_bynode_b4 37601/1711/3776/43088
cpubase_bynode_b3 43895/3099/4238/51232
cpubase_bynode_b2 66344/6674/6726/79744
cpubase_bynode_b1* 66344/6674/6726/79744
cpubase_interac 118/282/48/448
cpularge_bycore_b6 183/17/32/232
cpularge_bycore_b5 267/29/64/360
cpularge_bycore_b4 639/73/64/776
cpularge_bycore_b3 1424/296/248/1968
cpularge_bycore_b2 1456/296/248/2000
cpularge_bycore_b1 1456/296/248/2000
cpularge_bynode_b6 183/17/32/232
cpularge_bynode_b5 267/29/64/360
cpularge_bynode_b4 639/73/64/776
cpularge_bynode_b3 1023/209/128/1360
cpularge_bynode_b2 1456/296/248/2000
cpularge_bynode_b1 1456/296/248/2000
cpularge_interac 0/64/0/64
gpubase_bygpu_b6 648/664/96/1408
gpubase_bygpu_b5 1340/1326/150/2816
gpubase_bygpu_b4 2121/2129/358/4608
gpubase_bygpu_b3 2792/2690/534/6016
gpubase_bygpu_b2 3843/2783/726/7352
gpubase_bygpu_b1 3843/2783/726/7352
gpubase_bynode_b6 710/938/96/1744
gpubase_bynode_b5 1504/1834/174/3512
gpubase_bynode_b4 2450/2960/438/5848
gpubase_bynode_b3 3265/3665/614/7544
gpubase_bynode_b2 4438/3876/806/9120
gpubase_bynode_b1 4462/3876/806/9144
gpubase_interac 48/0/0/48
c-alex87 191/1/0/192
c-stelzer 3/189/0/192
c-awachs 313/839/144/1296
c-ccolijn 517/59/0/576
c-whkchun 0/608/0/608
c-tim 0/960/0/960
c-ut-atlas 0/192/0/192
cpubackfill 39235/2815/3374/45424
c12hbackfill 62214/7308/6094/75616
gpubackfill 3217/3089/590/6896
cpupreempt 62214/7308/6094/75616
gpupreempt 4342/3300/782/8424
Graham at Waterloo – no response from graham.calculcanada.ca?
Overall it looks like there are ~1,000s of CPUs idle on the other clusters, and ~10,000s of CPUs allocated.
What is the difference between Beluga and Narval and Rorqual?
| Characteristic | beluga | narval | rorqual |
|---|---|---|---|
| Age | Mar 2019 | Oct 2021 | June 2025 |
| main nodes | 579 | 1145 | 670 |
| cores per node | 40 | 64 | 192 |
| avail mem GB | 186 | 249 | 750 |
| CPU | Intel Gold 6148 Skylake | AMD Rome 7532 | AMD EPYC 9654 (Zen 4) |
| CPU GHz | 2.4 | 2.4 | 2.4 |
| GPU nodes | 172 | 159 | 81 |
| GPU type | 4 x NVidia V100SXM2 16G | 4 x NVidia A100SXM4 40G | 4 x NVidia H100 SXM5 80GB |
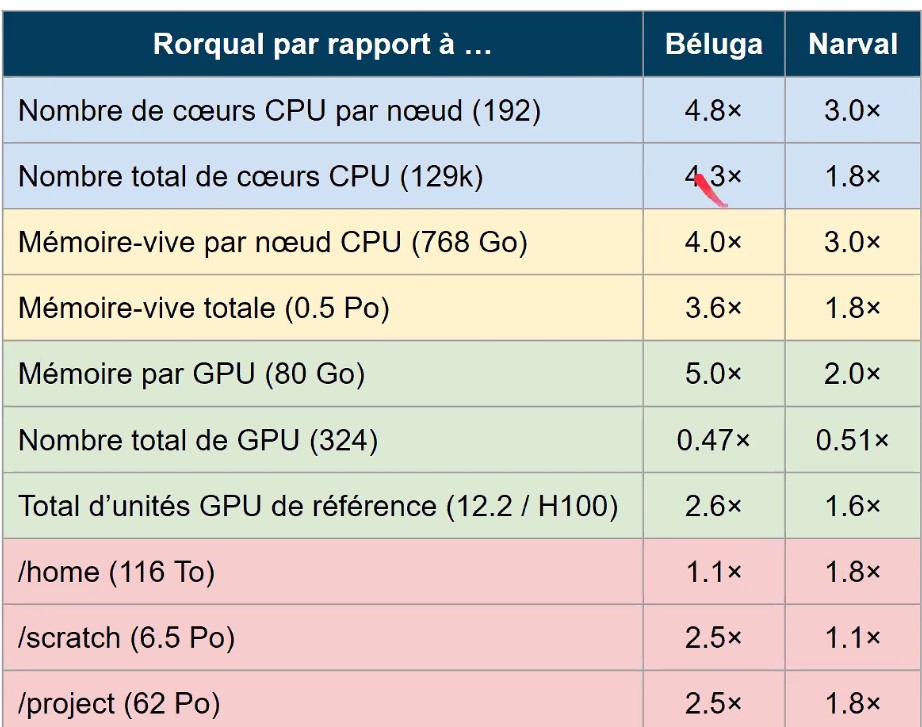
What about Rorqual?


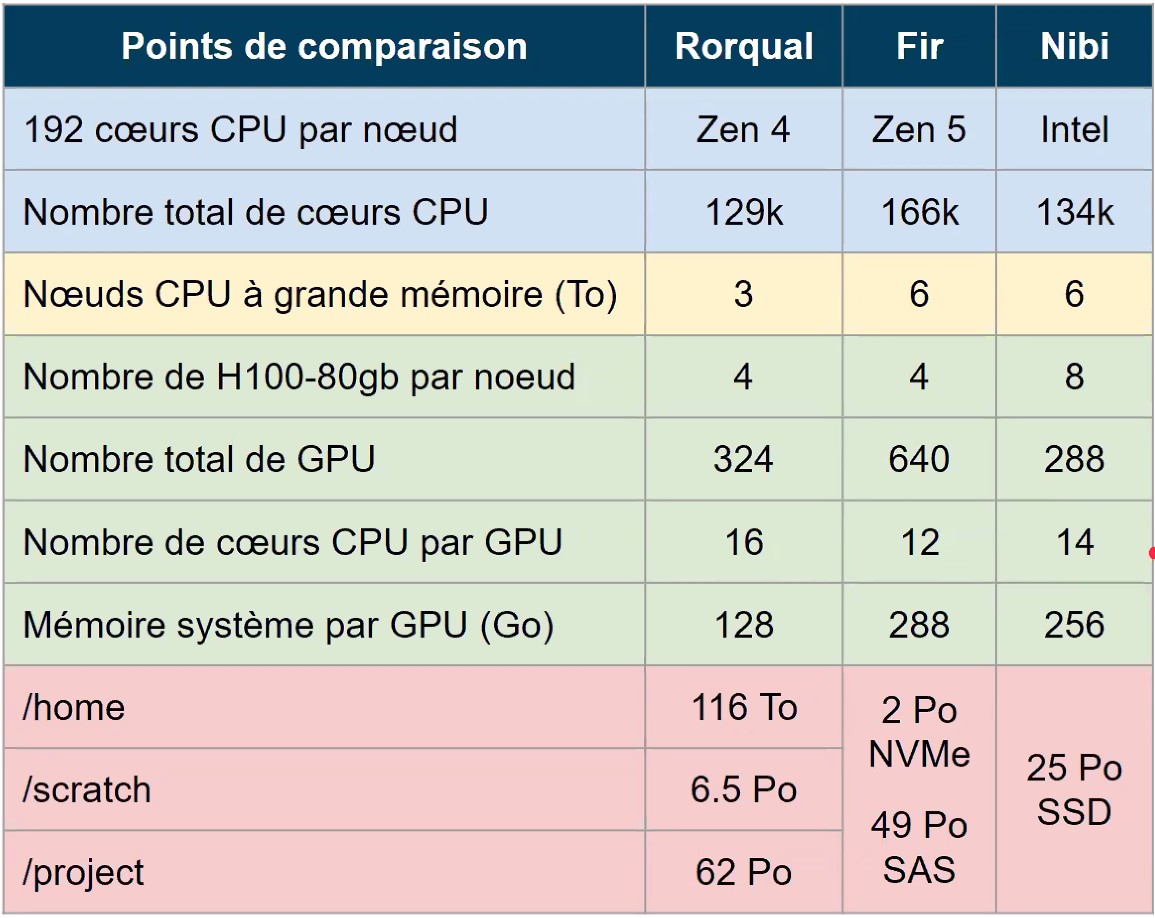
How to use the file systems efficiently?
La règle d’or, c’est de faire des grosses opérations. Éviter d’avoir des millions de petits fichiers, ou des petites écritures/lectures. Si vous avez un grand nombre de fichier, voyez les astuces ici: https://docs.alliancecan.ca/wiki/Handling_large_collections_of_files/fr Si vous avez des gros fichiers (minimum plusieurs centaines de mega-octets), faites des lectures et écritures d’un seul coup, plutôt que de lire/écrire ligne par ligne.
- /tmp - short term storage (done when job is done)
- /scratch - 30 day storage (for job IO)
- /projects - medium term storage (copy results here from scratch)
- /nearline - 10GB file size min, very slow, useful for long term storage.
How to transfer files to the cluster? Try globus.
How is the quota counted?
For the QC clusters (narval, rorqual) there is automatic compression, and the quota counts the size after compression. For the other clusters, quota is counted before compression.
cuda versions
Sinon dans mon cluster virtuel je vois
[tdhock@login1 ~]$ module spider cuda
cuda:
Versions:
cuda/10.1
cuda/10.2
Et sur narval je vois
[thocking@narval3 ~]$ module spider cuda
cuda:
Versions:
cuda/10.1
cuda/10.2
cuda/11.0
cuda/11.1.1
cuda/11.2.2
cuda/11.4
cuda/11.7
cuda/11.8.0
cuda/12.2
cuda/12.6
cuda/12.9
Et sur rorqual je vois
[thocking@rorqual1 ~]$ module spider cuda
cuda:
Versions:
cuda/11.8
cuda/12.2
cuda/12.6
cuda/12.9
| version | virtuel | narval | rorqual |
|---|---|---|---|
| 10.1 | y | y | |
| 10.2 | y | y | |
| 11.0 | y | ||
| 11.1.1 | y | ||
| 11.2.2 | y | ||
| 11.4 | y | ||
| 11.7 | y | ||
| 11.8(.0) | y | y | |
| 12.2 | y | y | |
| 12.6 | y | y | |
| 12.9 | y | y |